Linux系统编程
ch1-1 Linux-Basics
一、谈谈自己对linux的理解(#)
定义:根据GNU通用许可证开发的免费Unix类型的操作系统
特点:开源、受欢迎、支持大多数平台
历史:Unix 1969——GNU 1984——第一版 1991——发行版 1992
创始人:linus
发行版:RedHat(RHEL,CentOS),Debian(Ubuntu),Suse等。
GNU/Linux系统 = Linux内核 + GNU软件/库
二、分区形式(#)
1.MBR(Master Boot Record)主引导分区
512字节,0磁道第1扇区。
446字节引导代码(用于启动操作系统)
64字节磁盘分区表,最多4条目
2字节的0X55AA“魔数”
2.GPT和GUID
GPT与MBR并称两种分区类型。
GPT的全称是GUID Partition Table Scheme,即全局唯一标识分区表。
3.分区的限制和好处
限制:分区数目限制(4主分区或3主1扩),分区大小限制(受文件系统和操作系统限制)。
好处:数据保护、数据整理、系统管理、多操作系统。
MBR是传统分区方案,有诸多限制(如最大支持2TB硬盘,只能有4个主分区)。为了解决这些问题,出现了更现代的GPT分区方案,它是UEFI固件(替代传统BIOS)的标准配置,支持更大的硬盘和更多的分区。
三、文件系统的概念(#)
操作系统中负责访问和管理文件的部分
Linux常用文件系统:VFS、EXT2、EXT3、FAT32……
(原作者注:这里我实在受不了了,想吐槽一句,这PPT至少得有20年了,最常用的是EXT4,XFS,SWAP,EFI,VFAT等)
文件系统决定了数据如何在磁盘上组织和存储。Linux原生支持EXT系列(Extended File System),如EXT4是目前的主流。VFS是Linux的一个强大特性,它让用户和程序可以用同样的命令和接口去操作不同格式的文件系统(比如Windows的NTFS、U盘里的FAT32),无需关心底层差异。
四、分区(*)
至少要创建:
/(根分区),750MB(推荐1.5G或更多)Swap(交换分区),大小等于内存容量
推荐:/boot(16MB)
可能需要/想要创建的其他分区:
/usr,/usr/local,/var,/tmp,/opt,/home
Linux下默认的分区程序是 fdisk
这是安装时的分区建议。
/根分区是必须的,所有其他目录都在它下面。Swap分区用作虚拟内存,当物理内存不足时,系统会把不活跃的数据暂时放到Swap里。/boot存放内核和引导加载程序文件,单独分区有助于在某些情况下修复系统。/home存放用户个人数据,单独分区的好处是重装系统时可以保留用户数据不被格式化。
五、Linux启动流程(*)
-
BIOS:检查内存,从非易失性存储器加载选项,检查启动设备,加载启动设备的MBR并执行它。
-
MBR:包含一个“引导加载程序”和分区表。传统上由LILO/GRUB设置。
-
引导加载程序:将压缩的内核镜像加载到内存中。内核解压自身并启动……
-
Init进程:配置文件为
/etc/inittab,运行级别(runlevels)。
BIOS完成最基本的硬件自检,找到硬盘,读取MBR里的引导程序(如GRUB)。GRUB负责加载Linux内核到内存。内核初始化硬件后,启动第一个用户态进程——
init(在现代系统中常被systemd取代),init再根据配置启动各种服务,最终呈现登录界面。
补充:LILO与GRUB
LILO(Linux Loader):较老的引导加载程序,配置文件为 /etc/lilo.conf,每次修改配置后必须重新运行 lilo 命令更新MBR,否则改动不生效。
GRUB(GRand Unified Bootloader):目前主流的引导加载程序,分阶段存储——第一阶段在MBR,第1.5阶段和第二阶段在 /boot/grub。它能理解文件系统,不需要像LILO那样每次修改后"激活"配置。配置文件为 /boot/grub/grub.conf(现代版本多为 grub.cfg),通过 grub-install 安装到MBR。
GRUB可以传递启动参数给内核,可选择性地加载 initrd/initramfs(临时根文件系统,用于加载内核本身不含但必需的驱动),也可以启动其他操作系统(如双系统)。
六、安装软件(#)
1. 从源码编译安装
传统Autotools方式:
tar zxvf application.tar.gz # 解压源码包
cd application # 进入目录
./configure # 检查系统环境,生成Makefile
make # 编译源码
su - # 切换到root用户
make install # 安装到系统目录CMake方式(更现代):
tar zxvf application.tar.gz
cd application
mkdir build && cd build # 外部构建,避免污染源码目录
cmake .. # 生成构建系统
make VERBOSE=1 # 编译
su -
make install2. 包管理器安装
现代Linux最常用的方式,自动解决依赖关系。
- Debian/Ubuntu系:
apt-get(高层)、dpkg(底层)、aptitude - Red Hat/Fedora系:
yum/dnf(高层)、rpm(底层)
常用RPM命令:
rpm -qa:查询所有已安装的包rpm -ivh package-name:安装一个RPM包rpm -e package-name:卸载一个RPM包
从源码安装适合需要自定义编译选项的场景,但需要手动处理依赖。包管理器一键安装、自动解决依赖,是日常使用的主要方式。
七、命令行提示符和命令
1. 命令提示符
Linux系统上的所有操作都可以通过输入命令来完成,图形界面(X-Window)不是必需的。要在图形界面中输入命令,需要启动终端模拟器。
$:普通用户登录后的提示符#:root(超级管理员)登录后的提示符
提示符可以自行配置,由环境变量 PS1 控制。
命令语法:$ command option(s) argument(s) — 命令名 + 选项(以 - 开头,调整行为) + 参数(操作对象)。
示例:ls(无选项无参数)、ls -l(有选项)、ls /dev(有参数)、ls -l /dev(选项+参数)。
2. 多用户和多任务
Linux是多用户、多任务操作系统。多个用户可同时独立运行多个任务。使用系统前必须登录,用用户名和密码标识自己。
多种登录方式:控制台(本地终端)、串行终端、网络连接(SSH远程登录)。
虚拟终端:大多数Linux发行版的控制台模拟了多个虚拟终端,每个可以看作一个独立的终端,不同用户可使用不同的虚拟终端。典型设置:VT 1-6为文本模式登录,VT 7为图形模式登录提示。用 Ctrl+Alt+F1~F6 切换文本终端,Ctrl+Alt+F7 回图形界面。图形界面卡死时切换到文本终端杀进程非常实用。
3. 基本命令
passwd # 更改当前用户的登录密码
mkpasswd # 生成随机密码字符串
date # 查看系统当前日期和时间
cal # 显示日历
who # 查看当前登录到系统的所有用户
whoami # 查看当前用户名
finger # 查看用户的详细信息
clear # 清屏(或Ctrl+L)
echo # 向屏幕输出一行消息
write user # 向指定用户发送消息(对方通过mesg控制是否接收)
wall # write all,向所有登录用户广播消息
talk user # 与指定用户建立实时聊天会话
mesg n/y # 禁止/允许接收write和talk消息4. 目录相关命令
pwd # Print Working Directory,打印当前工作目录的绝对路径
cd dir # Change Directory,切换工作目录(cd ~回主目录,cd -回上次目录)
mkdir dir # 创建新目录
rmdir dir # 删除空目录(目录非空则失败,需用 rm -r)
ls # 列出目录内容
-l # 长格式:权限、硬链接数、所有者、大小、修改时间、文件名
-a # 显示所有文件,包括 . 和 .. 开头的隐藏文件
-R # 递归显示所有子目录的内容
-F # 在目录名后加/,可执行文件后加*,链接后加@5. 文件相关命令
touch file # 更新文件的时间戳为当前时间;若文件不存在则创建空文件
cp src dst # 复制文件;cp -r 递归复制整个目录
mv src dst # 移动文件到另一目录,或在同一目录下重命名
ln target link # 创建链接
默认 # 硬链接:新文件名与原文件共享同一inode和数据块
-s # 符号链接(软链接):存储目标路径,类似Windows快捷方式
rm file # 删除文件;rm -r 删目录;rm -rf 强制递归删除(极其危险!)
cat file # 将文件内容全部输出到屏幕(concatenate)
more file # 分页显示内容(只能前进,空格翻页)
mknod # 在/dev下创建驱动的设备文件节点
mkfifo # 创建命名管道文件(FIFO)
less file # 分页显示内容(可上下翻页/搜索,功能更强)
chmod # 修改文件权限(详见第十节)
find # 按条件查找文件(详见 ch1-2 第五节)6. 进程相关命令
ps # 报告当前进程状态
ps -e # 列出所有进程
ps aux # 显示所有进程及详细信息(用户、CPU、内存等)
pstree # 以ASCII树状图直观显示进程父子关系
jobs # 列出当前shell的后台作业
fg %n # 将后台作业n调到前台运行
bg %n # 将暂停的作业n放到后台继续运行
Ctrl+Z # 暂停当前前台进程并放入后台
kill -9 PID # 向进程发送SIGKILL信号(强制杀死,不能被进程捕获或忽略)
nohup cmd & # 忽略挂断信号运行命令,断开SSH后进程不终止
nice -n val cmd # 以指定优先级(-20最高,19最低,普通用户只能降级)启动程序
renice val PID # 调整已运行进程的优先级
top # 实时动态显示最占用CPU/内存的进程(类似Windows任务管理器)Shell本身也是一个进程,它读取你的命令并启动相应的进程。
echo $$可显示当前Shell的PID。
7. 获取帮助
遇到任何不懂的命令,首先尝试获取帮助,这是自学Linux最重要的能力。
man command # 查看命令的手册页(manual),最权威的帮助文档
man -k keyword # 按关键字搜索手册页(等同于apropos)
info command # GNU项目推荐的结构化文档,支持超链接式跳转
command --help # 多数命令支持,快速查看用法概览man手册的8个章节(同一关键词可能出现在多个章节):
| 章节 | 内容 | 示例 |
|---|---|---|
| 1 | 用户命令 | man 1 passwd — 修改密码的命令 |
| 2 | 系统调用 | man 2 open — open()系统调用 |
| 3 | C库函数 | man 3 printf — printf()函数 |
| 4 | 设备和特殊文件 | man 4 tty — 终端设备 |
| 5 | 文件格式和协议 | man 5 passwd — /etc/passwd文件格式 |
| 6 | 游戏 | — |
| 7 | 约定、宏包等 | man 7 signal — 信号概述 |
| 8 | 系统管理命令 | man 8 mount — mount管理命令 |
八、七种文件类型
1. 什么是文件
根据SUSv3标准定义:文件是一个可以被写入或读取的对象,具有某些属性,包括访问权限和类型。
文件结构一般分为三种:字节流、记录序列、记录树。在Linux中,文件就是字节流——系统不关心文件内部是什么结构,全部视为一串连续的字节。这种简单的抽象赋予了Linux极大的灵活性,无论是文本、图片、可执行程序还是硬件设备,统统可以用"文件"的方式操作。
2. Linux"一切皆文件"哲学
这是Linux最重要的设计思想之一。普通文件、目录、硬件设备、网络通信端点都被抽象成文件,可以用同样的API(open、read、write、close)来操作。/dev 目录下的设备文件就是这种思想的典型体现。
3. 七种文件类型
| 类型 | ls -l首字符 |
说明 |
|---|---|---|
| 普通文件(regular) | - |
文本或二进制数据,无特定内部结构,最常见的文件类型 |
| 目录文件(directory) | d |
一个目录表,记录该目录下所有文件的名称及其inode号,用于定位文件 |
| 字符特殊文件(character) | c |
代表字符设备(按字节/字符流传输),如键盘、串口、终端,位于 /dev |
| 块特殊文件(block) | b |
代表块设备(按固定大小的块传输,可随机访问),如硬盘、U盘,位于 /dev |
| 套接字(socket) | s |
进程间网络通信的端点,也用于同一台机器上的进程间通信 |
| 符号链接(symbolic link) | l |
包含指向另一个文件的路径名(而非实际数据),类似Windows快捷方式 |
| 命名管道(FIFO) | p |
用于无关进程间通信的特殊文件,数据按先进先出(First In First Out)传递 |
判断文件类型可以用
ls -l看首字符,或用file命令探测实际内容类型(如file /bin/ls输出ELF 64-bit executable)。
九、目录结构
1. 统一的文件系统
Linux与Windows最大的不同之一:没有盘符(C:、D:)的概念。所有Linux目录都包含在一个虚拟的、统一的文件系统中,以 / 为根,一切皆从根开始。
物理设备(软盘、硬盘分区、CD-ROM、U盘等)必须通过挂载(mount)操作,附加到根文件系统下的某个目录(称为挂载点)上才能访问。例如,你可以把第二块硬盘挂载到 /data 目录,之后访问 /data 就等于访问那块硬盘。
这就解释了为什么Linux的目录树是一棵单一的树,而Windows是多个盘符各自独立的树。
2. 文件系统层次标准(FHS)
FHS(Filesystem Hierarchy Standard,网址:http://www.pathname.com/fhs)规定了每个目录应该存放什么类型的文件,使得不同Linux发行版之间保持高度一致性。
| 目录 | 全称/含义 | 用途 |
|---|---|---|
/ |
root | 根目录,整个文件系统的起点,所有其他目录都在它之下 |
/bin |
binaries | 普通用户和系统管理员共用的基本命令(ls, cp, cat, bash等) |
/sbin |
system binaries | 系统管理员专用管理命令(fdisk, shutdown, mount等) |
/boot |
boot | 内核文件(vmlinuz)和引导加载程序文件(grub配置) |
/dev |
devices | 设备文件,所有硬件(硬盘、键盘、终端等)都抽象为文件存放于此 |
/etc |
et cetera | 系统和服务的配置文件(如 /etc/passwd、/etc/fstab) |
/home |
home | 普通用户的个人目录(/home/username),存放各自的文档和数据 |
/lib |
libraries | 系统启动和基本命令所需的共享库文件(.so) |
/mnt |
mount | 临时挂载点,用于手动挂载临时设备(如光驱、U盘) |
/proc |
process | 虚拟文件系统,不占用磁盘,提供内核、进程、硬件等运行时信息 |
/root |
root home | root超级用户的个人目录(与/根目录不同!) |
/tmp |
temporary | 临时文件目录,所有用户可读写,重启后可能被清除 |
/usr |
Unix System Resources | 系统主要应用程序、库、文档等(通常最大的目录),/usr/local 存放本地编译安装的软件 |
/var |
variable | 经常变化的数据:日志(/var/log)、邮件队列、打印队列、数据库等 |
在实际考试/面试中,常考
/etc、/var、/proc、/home这几个目录的用途。
十、文件权限
1. 三个访问级别
- 用户(User):文件的所有者
- 组(Group):拥有该文件的组中的所有用户
- 其他人(Others):所有其他用户
2. 三种权限
| 权限 | 对文件 | 对目录 |
|---|---|---|
| r(读) | 读取文件内容 | 列出目录内容 |
| w(写) | 修改文件内容 | 在目录中创建/删除文件 |
| x(执行) | 作为程序执行 | 进入该目录(cd进去) |
3. 查看权限
ls -l 输出的第一列即为权限字符串,如 -rwxr-xr--:
- 第1个字符:文件类型(
-普通文件,d目录,l符号链接) - 后面9个字符,每3位一组,分别代表User、Group、Others的权限
4. 修改权限
符号模式:chmod <who><operator><what> filename
- who:
u所有者,g组,o其他人,a全部 - operator:
+添加,-移除,=设置为 - what:
r读,w写,x执行
示例:chmod u+x file 给所有者加执行权限;chmod go-w file 移除组和其他人的写权限
八进制模式(更常用):每个权限对应一个数字(r=4, w=2, x=1)
| User | Group | Others | |
|---|---|---|---|
| 符号 | rwx | r-x | r– |
| 二进制 | 111 | 101 | 100 |
| 八进制 | 7 | 5 | 4 |
示例:chmod 755 file = 所有者全权限,组和其他人读+执行;chmod 777 file = 所有人全权限
5. 默认权限
- 新建文件默认:
-rw-r--r--(644)——没有执行权限 - 新建目录默认:
drwxr-xr-x(755)
由 umask 值控制,umask默认值通常为022。计算公式:
- 普通文件:666 - umask = 最终权限(如 666-022=644)
- 目录文件:777 - umask = 最终权限(如 777-022=755)
十一、进程概念(*)
定义:进程是一个正在执行的任务/程序实例。包含程序的代码、数据、堆栈、寄存器状态等(SUSv3标准:一个地址空间,其中有一个或多个线程执行,以及这些线程所需的系统资源)。
程序和进程的区别:程序是磁盘上的静态文件,进程是程序的一次动态执行。
进程包含的信息:程序名称、用户/组ID、打开的文件、当前目录、进程ID(PID)、父进程ID(PPID)、程序变量等。
进程的启动和终止:
- 所有进程由其他进程启动(父子关系),形成树状层次结构
- 例外:
init(PID为1,现代系统多为systemd)由内核直接启动,是所有用户进程的祖先 - 终止方式:①进程自己完成后终止 ②被另一个进程通过信号终止
- 常见信号:
SIGTERM(15) 请求终止,SIGKILL(9) 强制杀死
守护进程(Daemon):在后台持续运行、永不结束的系统进程,通常以字母 d 结尾(如 sshd、httpd、mysqld)。系统启动时自动运行,持续提供服务。
ch1-2 Linux-Basics
一、层次图(#)
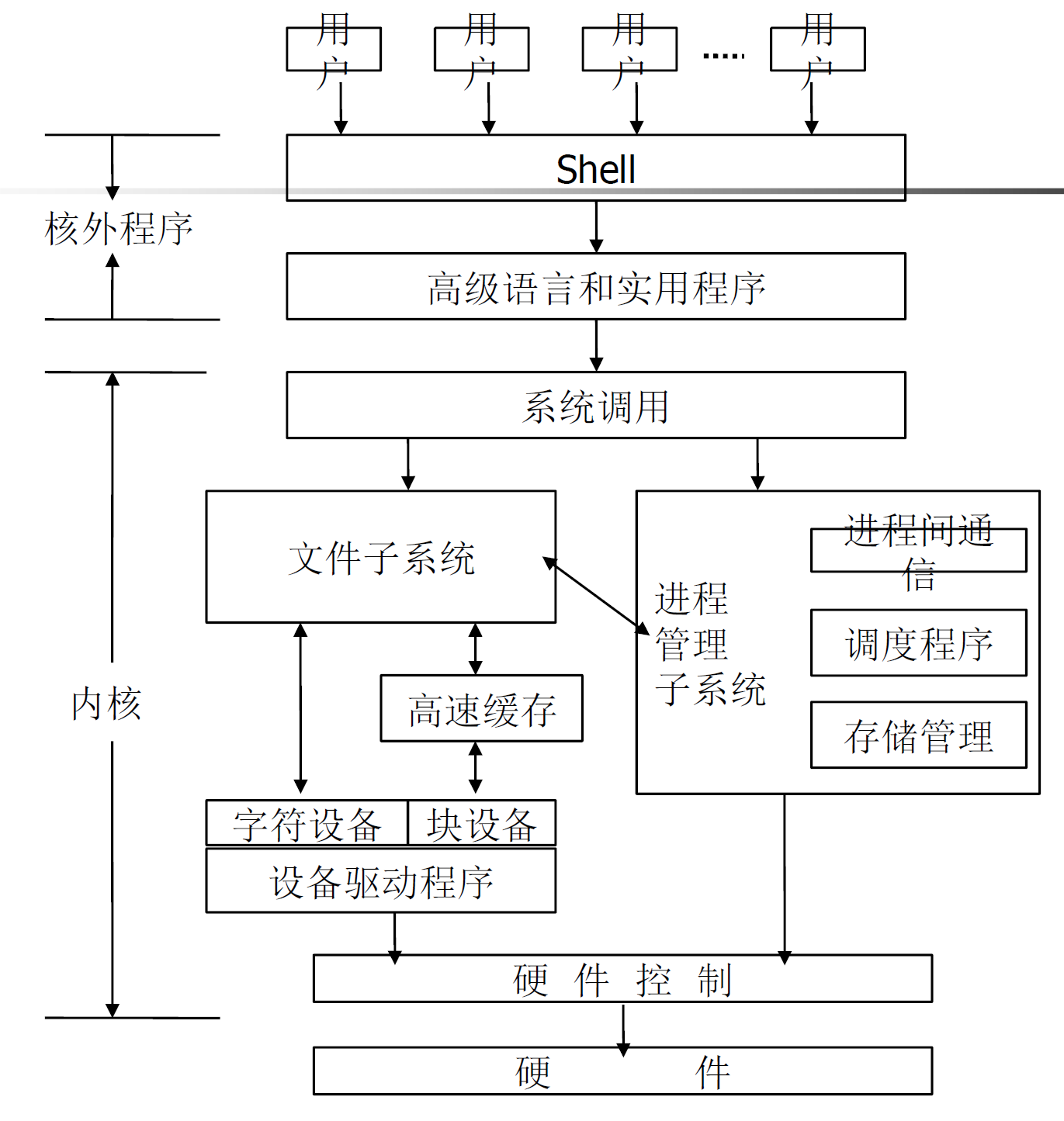
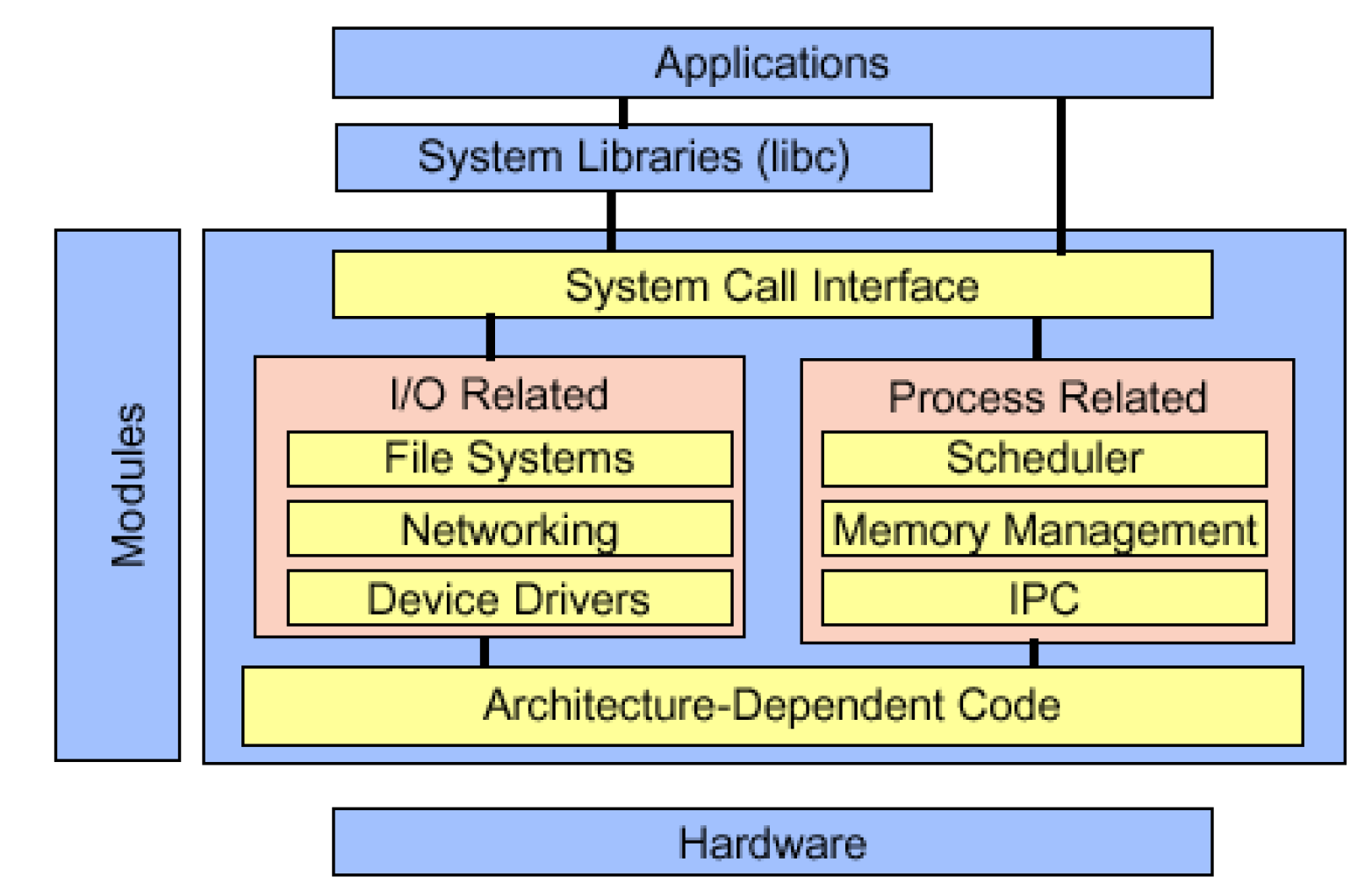
这两张图展示了Linux系统的层次结构。最底层是硬件,往上是内核(管理CPU、内存、设备、文件系统等),再往上是系统调用接口,最上层是用户空间的应用程序和Shell。用户程序通过系统调用与内核交互,不能直接操作硬件。
二、重定向
重定向将命令的输入/输出从默认位置转移到另一个位置。
1. 三个标准流
| 名称 | 文件描述符 | C语言变量 | 默认来源/去向 |
|---|---|---|---|
| 标准输入(stdin) | 0 | stdin |
键盘 |
| 标准输出(stdout) | 1 | stdout |
屏幕 |
| 标准错误(stderr) | 2 | stderr |
屏幕 |
stdout和stderr虽然默认都输出到屏幕,但它们是两个独立的通道。stdout走正常输出,stderr走错误输出,重定向时可以分开处理。
2. 基本重定向符号
command > file # 标准输出重定向到file(覆盖原内容)
command >> file # 标准输出追加到file末尾
command < file # 从file读取输入代替键盘
command 2> file # 标准错误重定向到file
command 2>> file # 标准错误追加重定向到file
<< # 追加输入重定向(here document)3. 关键示例
分开保存stdout和stderr:
kill -HUP 1234 > killout.txt 2> killerr.txt
# 正常输出 → killout.txt,错误信息 → killerr.txt,互不干扰合并stdout和stderr到同一文件:
kill -HUP 1234 > killout.txt 2>&1
# 2>&1 意思是:让文件描述符2(stderr)指向文件描述符1(stdout)当前指向的位置
# 即stderr也跟着stdout一起写入killout.txt⚠️ 顺序很重要:
2>&1必须写在> file的后面。如果写成2>&1 > file,stderr会指向重定向之前的stdout位置(即屏幕),不受后面> file的影响。
同时重定向stdin和stdout:
command < file1 > file2
# stdin从file1读,stdout写file2重定向的本质是改变文件描述符的指向。
&1中的&表示"文件描述符",2>&1不是"把stderr写入名为1的文件",而是"让stderr跟stdout走同一个地方"。重定向的底层实现是
dup2系统调用:将进程的文件描述符进行复制和覆盖,从而改变stdin/stdout/stderr的去向。
cat重定向 vs cat文件名(重要辨析)
cat < abc.txt # 重定向:Shell打开文件,将stdin指向该文件
cat abc.txt # 参数传递:cat自己打开并读取文件两者执行流程完全不同:
cat abc.txt:Shell把abc.txt作为参数传给cat(main(int argc, char** argv)中argc > 0),cat内部调用open打开文件并读取输出cat < abc.txt:Shell先调用dup2将stdin重定向到abc.txt,然后执行cat(此时argc == 0),cat从stdin读取数据输出
一言蔽之:前者Shell打开文件让cat读stdin,后者cat自己打开文件自己读。
三、管道
管道(|)将一个进程的标准输出直接作为另一个进程的标准输入,体现了"小工具组合解决大问题"的Unix哲学。
示例一:统计文件数
ls | wc -l
# ls列出文件名 → wc -l统计行数 → 结果即文件总数示例二:筛选目录项
ls -lF | grep ^d
# ls -lF 详细列表,目录名后加/标记
# grep ^d 筛选以 d 开头的行(即只保留目录)
# 最终只显示目录示例三:多级流水线
ar t /usr/lib/libc.a | grep printf | pr -4 -t
# ar t 列出静态库libc.a中所有目标文件(.o)
# grep 筛选出名字含"printf"的文件
# pr -4 将结果分成4列打印(-t不打印页眉页脚)管道和重定向可以任意组合,如
ls -l | grep "txt" > result.txt。
四、环境变量
环境变量是操作环境的参数,影响程序运行时的行为,类似于Windows的系统变量。
1. 查看环境变量
echo $HOME # 打印当前用户的主目录路径
echo $PATH # 查看命令搜索路径
echo $SHELL # 查看当前使用的shell
env # 只显示环境变量
set # 显示所有变量(环境变量 + shell局部变量)
envvsset:env只列环境变量(被子进程继承的),set列出所有变量包括shell内部的局部变量。
2. PATH 详解
当你在终端输入一个命令时,shell会按照 PATH 中列出的目录顺序逐个查找该命令的可执行文件。冒号 : 是分隔符。
$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/home/song/bin修改PATH:
PATH=$PATH:. # 在原有PATH末尾加上当前目录.
export PATH # 导出为环境变量,使子进程也能看到这个改动⚠️ 把
.(当前目录)加入PATH存在安全隐患——恶意程序可能伪装成常用命令(如把木马命名为ls放在当前目录),生产环境不建议这样做。
export 的作用:不加 export 的修改只在当前shell有效,启动的子shell看不到;加了 export 后修改会传递给子进程。
3. 常见环境变量
| 变量 | 含义 |
|---|---|
HOME |
当前用户的主目录 |
PATH |
以冒号分隔的命令搜索路径列表 |
SHELL |
当前用户的默认shell(如 /bin/bash) |
USER |
当前用户名 |
PWD |
当前工作目录 |
4. 设置环境变量
export name="value" # 临时设置,退出shell后失效5. 系统环境变量 vs 用户环境变量
| 类型 | 文件位置 | 说明 |
|---|---|---|
| 系统环境变量 | /etc/profile、/etc/bashrc |
对所有用户生效 |
| 用户环境变量 | ~/.bash_profile、~/.bashrc |
仅对当前用户生效 |
.bash_profile:用户登录时被读取和执行.bashrc:每次启动新shell时读取和执行
五、简单的正则与高级命令(#)
老师原话:只考最简单的。掌握基本用法即可,参考书籍:《精通正则表达式》。
grep "pattern" file # 在文件中搜索匹配模式的行
-i 忽略大小写
-v 反向匹配(显示不匹配的行)
-r 递归搜索目录
-E 启用扩展正则(等同于egrep)
find /path -name "*.txt" # 按文件名查找
-type d / -type f # 只查目录/只查普通文件
-size +1M # 查找大于1MB的文件
sed 's/old/new/g' file # 流编辑器,非交互式替换文本
sort file # 按行排序(-n按数值,-r逆序,-u去重)
uniq file # 去除相邻重复行(通常先sort再uniq)
wc -l / -w / -c file # 统计行数/单词数/字符数
head -n N / tail -n N file # 查看文件头/尾N行
tail -f file # 实时追踪文件末尾(看日志常用)
cut -d":" -f1 file # 以:为分隔符,提取第1列
file filename # 探测文件真实类型这些命令通过管道组合产生强大效果,如
cat /etc/passwd | cut -d: -f1 | sort | uniq。
ch2 Shell Programming
Shell是用户与操作系统的接口,作为核外程序存在。Shell具有双重角色:
- 命令解释程序(Command Interpreter):打印提示符 → 解析命令行 → 查找文件 → 准备参数 → 执行命令
- 程序设计语言解释器(Programming Language Interpreter):支持变量、条件、循环、函数等编程结构
一、常见的shell(*)
Linux下有多种Shell,各有特点。常见的有:
| Shell | 说明 |
|---|---|
| bash | “Bourne Again Shell”,GNU项目出品,Linux默认且最常用的Shell |
| sh | 通常是指向bash的符号链接(bash以sh运行时模拟经典sh行为) |
| csh / tcsh | C Shell,语法风格类似C语言 |
| ksh | Korn Shell,AT&T开发 |
/bin/sh在现代Linux发行版中通常是bash的符号链接,但在嵌入式系统中可能是ash等轻量实现。
二、编写脚本文件
1. 预备知识
Shebang
#!/bin/bash 是脚本文件第一行的特殊指令,称为shebang(或sha-bang)。它告诉操作系统该使用哪个解释器来执行这个脚本。
#!/bin/bash # 用bash解释
#!/bin/sh # 用sh解释
#!/usr/bin/python3 # 用python解释注释
以 # 开头的行(shebang除外,那是给操作系统看的)。
退出码
每个程序/脚本结束时会返回一个数字给调用者,称为退出码(exit code):
0:成功- 非零:错误(1~255,不同值可表示不同错误)
exit 0 # 脚本成功结束
exit 1 # 脚本以错误状态1退出Shell中 $? 变量保存上一条命令的退出码。
执行脚本的三种方式
sh script_file # 显式调用sh解释器,脚本不需可执行权限
chmod +x script_file && ./script_file # 加可执行权限后直接运行,shebang生效
source script_file # 在当前Shell进程中执行(不启动子Shell)
. script_file # 等同于source
source(或.)与另两种方式的关键区别:在当前Shell中执行,脚本中对环境变量的修改会影响当前Shell。常用于加载配置文件(如source ~/.bashrc)。
用户环境
三个bash用户级配置文件:
| 文件 | 触发时机 |
|---|---|
~/.bash_profile |
用户登录时读取并执行(如通过tty或SSH登录) |
~/.bashrc |
每次启动新的交互式非登录Shell时执行(如打开终端窗口) |
~/.bash_logout |
登录退出时执行(可用于清理临时任务) |
通常在 .bash_profile 中会主动 source ~/.bashrc 以保证环境一致。
alias ll='ls -l' # 创建命令别名
unalias ll # 删除别名
export MY_VAR="Hello" # 导出变量为环境变量(使子进程可见)2. 变量
Shell变量分为三类:用户变量(脚本自定义)、环境变量(系统提供的全局变量)、参数变量(脚本运行时自动设置)。
用户变量
赋值和引用:
var=value # 赋值:等号两边不能有空格!
echo $var # 引用:$加变量名read 命令
从标准输入读取一行存入变量,是Shell脚本最常用的交互方式。
基本用法:
echo -n "Enter your name: " # -n 抑制末尾换行,让提示和输入在同一行
read name
echo "hello $name"常用选项:
read -p "Enter: " var # -p:直接在read中指定提示文字
read var # 省略变量名时,输入存入默认变量 $REPLY
read -t 5 -p "Name: " name # -t N:超时N秒无输入则返回非零
read -s -p "Password: " pwd # -s:静默模式,输入不回显(适合密码)
read -n1 -p "[Y/N]? " ans # -n N:读取N个字符后自动结束,无需按回车
read -a arr # -a:将输入按字段分裂后存入数组
read -r line # -r:禁止反斜杠转义
read -N 10 line # -N N:强制读满N个字符(换行算一个字符)
read -d ":" line # -d delim:指定读取行的结束符号(默认换行)引号和转义
这是Shell引用机制的核心,决定哪些字符被解释、哪些保持原样:
| 引用方式 | 效果 |
|---|---|
单引号 '...' |
强引用:所有字符保持本身含义,$ 就是 $,\ 就是 \ |
双引号 "..." |
弱引用:$(变量引用)、反引号(命令替换)、\ 仍保留特殊含义,其余字符保持字面 |
反斜杠 \ |
转义紧跟其后的单个字符 |
echo '$HOME' # 输出:$HOME(变量不展开)
echo "$HOME" # 输出:/home/user(变量展开)
echo \$HOME # 输出:$HOME(\$被转义为普通字符)环境变量
Shell环境提供的全局变量,通常大写命名,通过 export 传递给子进程:
| 变量 | 含义 |
|---|---|
$HOME |
当前用户的登录目录 |
$PATH |
以冒号分隔的命令搜索目录列表 |
$PS1 |
命令行提示符,通常为 $(可自定义,如 [\u@\h \W]\$ ) |
$PS2 |
辅助提示符,提示后续输入,通常为 > |
$IFS |
输入字段分隔符,默认是空格、制表符和换行符 |
参数变量和内部变量
脚本运行时自动设置,用于获取命令行参数:
| 变量 | 含义 |
|---|---|
$# |
传递给脚本的参数个数 |
$0 |
脚本程序的名字(可能包含路径) |
$1 ~ $9 |
第1到第9个参数 |
$* |
全体参数组成的清单,各参数用 IFS 的第一个字符分隔(一个整体) |
$@ |
$* 的变体,不使用IFS,每个参数被独立引号包围 |
"$*"vs"$@":"$*"将所有参数变成一个字符串;"$@"将每个参数视为独立字符串。脚本中推荐使用"$@",可以正确传递含空格的参数。
示例——脚本 test.sh 内容:
#!/bin/bash
echo "The first parameter is $1"
echo "The second parameter is $2"
echo "The number of parameters is $#"
echo "All parameters are $*"
echo "The script name is $0"
exit 0运行 ./test.sh apple orange banana 输出:
The first parameter is apple
The second parameter is orange
The number of parameters is 3
All parameters are apple orange banana
The script name is ./test.sh3. 条件测试
Shell中的条件判断依赖于命令的退出码——0表示真,非0表示假(这与C语言相反)。
test 命令和 [ ] 语法
test expression 和 [ expression ] 完全等价。如果表达式为真,test 返回0(真);否则返回非0(假)。
⚠️ 语法细节:
[后面和]前面必须有空格![$a = "yes"]是错误的。
字符串比较
| 测试 | 含义 |
|---|---|
str1 = str2 |
两个字符串相同则为真(注意:一个等号!) |
str1 != str2 |
两个字符串不同则为真 |
-z str |
字符串长度为0(为空)则为真 |
-n str |
字符串长度非0(不为空)则为真 |
变量最好用双引号括起:
[ "$str" = "hello" ],防止变量为空或含空格导致语法错误。
算术比较
| 测试 | 含义 |
|---|---|
expr1 -eq expr2 |
相等(equal) |
expr1 -ne expr2 |
不等(not equal) |
expr1 -gt expr2 |
大于(greater than) |
expr1 -ge expr2 |
大于等于(greater or equal) |
expr1 -lt expr2 |
小于(less than) |
expr1 -le expr2 |
小于等于(less or equal) |
不能用
><做算术比较,因为在[ ]内部它们会被解释为重定向符号。只能用字母形式-gt、-lt等。
文件条件测试
| 测试 | 含义 |
|---|---|
-e file |
文件存在则为真 |
-d file |
文件是一个目录则为真 |
-f file |
文件是一个普通文件则为真 |
-s file |
文件长度不为0则为真 |
-r file |
文件可读则为真 |
-w file |
文件可写则为真 |
-x file |
文件可执行则为真 |
逻辑操作
| 操作 | 含义 |
|---|---|
! expr |
逻辑取反 |
expr1 -a expr2 |
逻辑与(and) |
expr1 -o expr2 |
逻辑或(or) |
在
[ ]外部,推荐使用&&和||组合多个条件,如:[ -f "$f" ] && [ -r "$f" ]。
4. 条件语句
if 语句
if [ expression ]; then
statements
elif [ expression ]; then
statements
else
statements
fi
then可以写在if同一行(前面加分号;),也可以换行写。fi是if的反写。
示例1(.bash_profile中常见):
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi示例2(交互式判断):
#!/bin/sh
echo "Is this morning? Please answer yes or no."
read answer
if [ "$answer" = "yes" ]; then
echo "Good morning"
elif [ "$answer" = "no" ]; then
echo "Good afternoon"
else
echo "Sorry, $answer not recognized."
exit 1
fi
exit 0case 语句
用于多重分支选择,比多个 elif 更清晰:
case str in
pattern1 | pattern2) statements;;
pattern3) statements;;
*) statements;; # 通配符,匹配所有剩余情况
esac每个模式后的命令以双分号 ;; 结束,| 表示"或"。esac 是 case 的反写。
示例:
#!/bin/sh
read -p "Is this morning? " answer
case "$answer" in
yes | y | Yes | YES) echo "Good morning!";;
no | n | No | NO ) echo "Good afternoon!";;
*) echo "Sorry, answer not recognized.";;
esac
exit 05. 循环语句
for 循环
对列表中的每个元素执行一次循环:
for var in list; do
statements
donelist 可以是空格分隔的字符串、通配符展开结果、或命令替换输出。
#!/bin/sh
for file in *.sh; do # 通配符展开,遍历所有.sh文件
echo "Processing $file"
done
exit 0用通配符
for file in *.sh比for file in $(ls *.sh)更安全——后者在文件名含空格时会出错。
while 循环
只要条件为真(退出码0)就继续循环:
while condition; do
statements
done带 break 提前退出的例子:
a=0
while [ "$a" -le "$LIMIT" ]; do
a=$(($a + 1))
if [ "$a" -gt 2 ]; then
break # 跳出整个循环
fi
echo -n "$a" # 只会输出 12(a>2后break退出)
donebreak 跳出整个循环,continue 跳过当前迭代进入下一次循环。
until 循环(不推荐)
与 while 相反——条件为假时执行循环,直到条件为真才停止:
until condition; do
statements
done语义容易混淆,建议用
while ! condition替代。
select 语句
bash特有的菜单生成语句,自动显示带编号的列表:
select item in itemlist; do
statements
done示例:
#!/bin/bash
clear
select item in Continue Finish; do
case "$item" in
Continue) ;;
Finish) break;;
*) echo "Wrong choice! Please select again!";;
esac
done运行时显示:
1) Continue
2) Finish
#?用户输入数字后,$item 获取对应的文本。选择 Finish 时 break 退出循环。
6. 命令表和语句块
命令表(命令串联)
command1; command2; command3 # 分号串联:无论成败,依次执行
stmt1 && stmt2 && stmt3 # AND命令表:前一成功(退出0)才执行后一
stmt1 || stmt2 || stmt3 # OR命令表:前一失败(退出非0)才执行后一
&&和||体现了短路求值。make && make install是最常见的用法——只有编译成功才安装。
语句块
用花括号将多个命令组合在一个上下文中执行:
{
statement1
statement2
}注意:花括号前后要有空格,内部最后一个命令必须以分号结束(同行时)。
7. 函数
Shell函数相当于脚本内的子程序,是语句块的主要载体。
定义和调用
func() {
statements
return 0 # 返回退出码(0~255),调用者通过 $? 获取
}
func para1 para2 # 调用函数并传参(参数在函数内通过 $1, $2... 访问)函数内可使用 local 关键字声明局部变量,只在函数内部有效:
local var="value" # 不影响函数外同名变量示例:通用的yes/no提示函数
yesno() {
msg="$1" # 第一个参数:提示消息
def="$2" # 第二个参数:默认返回值(0是,1否)
while true; do
echo "$msg"
read answer
case "$answer" in
y|Y|yes|YES) return 0;; # 用户确认
n|N|no|NO) return 1;; # 用户拒绝
"") if [ -n "$def" ]; then # 用户直接回车且有默认值
return $def
fi;;
esac
echo "ERROR: Invalid response, expected \"yes\" or \"no\"."
done
}调用示例:
if yesno "Continue installation? [n]" 1; then
: # 空命令,什么都不做,继续执行
else
exit 1
fi8. 其它常用命令和技巧
杂项命令
| 命令 | 作用 |
|---|---|
break |
从 for/while/until 循环中跳出 |
continue |
跳到当前循环的下一次迭代 |
exit n |
以退出码 n 退出脚本 |
return |
从函数中返回(带退出码) |
export var |
将变量导出为环境变量,使子进程可见 |
set |
为Shell设置参数变量 |
unset var |
从环境中删除变量或函数 |
trap 'cmd' SIG |
捕获信号,收到指定信号时执行cmd(如 trap 'cleanup' EXIT) |
: |
空命令,永远返回0,常用于占位或 while :; do ... done |
. 或 source |
在当前Shell中执行脚本(不启动子进程) |
命令替换
将命令的输出作为值嵌入到其他命令或变量中:
语法:$(command) 或 `command` (推荐 $(),嵌套更清晰)
echo "The current directory is $(pwd)"
echo "The current directory is $PWD" # 结果相同,但 $PWD 是变量而非命令
$(pwd)和$PWD的区别:在子Shell中,$PWD可能保留父Shell的值,而$(pwd)始终返回当前真实路径。
算术扩展
$((...)) 用于整数算术运算,变量名前 $ 可省略:
x=0
while [ "$x" -ne 10 ]; do
echo $x
x=$(($x + 1)) # 支持 + - * / %
done参数扩展
用于字符串处理,是Shell中非常强大的功能:
| 扩展形式 | 说明 |
|---|---|
${var:-default} |
若var为空或未定义,使用default值(不修改变量本身) |
${#var} |
返回var值的字符长度 |
${var%pattern} |
从尾部删除匹配pattern的最短部分 |
${var%%pattern} |
从尾部删除匹配pattern的最长部分 |
${var#pattern} |
从头部删除匹配pattern的最短部分 |
${var##pattern} |
从头部删除匹配pattern的最长部分 |
实用示例:
file="backup.tar.gz"
echo ${file%.*} # 去掉最短尾部匹配.* → backup.tar
echo ${file%%.*} # 去掉最长尾部匹配.* → backup
echo ${file##*.} # 去掉最长头部匹配*. → gz
path="/home/user/docs/file.txt"
echo ${path##*/} # 提取文件名:file.txt(去掉最长头部匹配*/)
echo ${path%/*} # 提取目录:/home/user/docs
# 批处理文件(创建 1_tmp ~ 9_tmp)
i=1
while [ "$i" -ne 10 ]; do
touch "${i}_tmp" # {}明确变量名边界
i=$(($i + 1))
doneHere Document(即时文档)
在脚本中嵌入多行文本作为命令输入:
#!/bin/bash
cat >> file.txt << !CATINPUT!
Hello, this is a here document.
It can contain multiple lines.
!CATINPUT!<< 后跟一个定界符(如 !CATINPUT!),直到遇到独立的定界符为止的所有内容,都被当作标准输入传给前面的命令。上述例子将两行文本追加到 file.txt 末尾。
ch3-0 Programming Prerequisite
一、编程工具(*)
Linux下典型的开发工具链:
| 工具 | 用途 |
|---|---|
| vi / emacs | 文本编辑器 |
| gcc | 编译和链接(GNU Compiler Collection) |
| gdb | 调试器(GNU Debugger) |
| make | 自动化构建工具 |
| CVS / Git | 版本控制 |
其他二进制工具:as(汇编器)、ld(链接器)、ar(创建静态库)、ldd(查看动态库依赖)。
二、编程语言(*)
分类
- 脚本语言:Shell(sh/bash/csh/ksh)、Perl、Python、tcl/tk、sed、awk
- 高级语言:C/C++、Java、Fortran
执行方式
| 方式 | 原理 | 代表语言 |
|---|---|---|
| 编译执行 | 先编译成本地字节码,再经解释器转为CPU可执行的二进制码 | C、C++、Go、Rust、Swift |
| 解释执行 | 不编译,读一行执行一行 | Python、Ruby、JavaScript、Perl、PHP |
Java比较特殊:先编译成字节码(.class),再由JVM解释执行,属于"编译+解释"的混合模式。
ELF格式
ELF(Executable and Linkable Format)是Linux/Unix下可执行文件和共享库的标准二进制封装格式,具有良好的可扩展性和跨平台性。
三、gdb功能
GDB(GNU Debugger)是Linux下最常用的调试工具,用于调试C、C++、汇编等语言编写的程序。使用前必须用 gcc -g 编译以包含调试符号信息。
核心功能
- 设置断点(breakpoint):让程序在指定位置暂停
- 监视变量值:查看运行中变量的当前值
- 单步执行:逐行执行代码,观察执行流程
- 修改变量值:在调试时临时更改变量值以测试不同情况
常用命令
| 命令 | 说明 |
|---|---|
file |
打开要调试的可执行文件 |
break / tbreak |
设置断点(行号/函数名/地址);tbreak为临时断点,命中一次后自动删除 |
run |
开始执行当前调试的程序 |
list |
列出当前位置附近的源代码 |
next |
执行下一条语句,不进入函数内部(step over) |
step |
执行下一条语句,若为函数调用则进入函数内部(step into) |
display |
设置表达式,每次程序停顿时自动显示其值 |
print |
临时显示一次表达式的值 |
kill |
中止正在调试的程序 |
quit |
退出gdb |
shell |
不退出gdb就执行shell命令 |
make |
不退出gdb就执行make命令 |
nextvsstep:前者把函数调用当作一个整体一步执行完;后者进入被调用函数内部逐行执行。
displayvs
四、编译链接图解
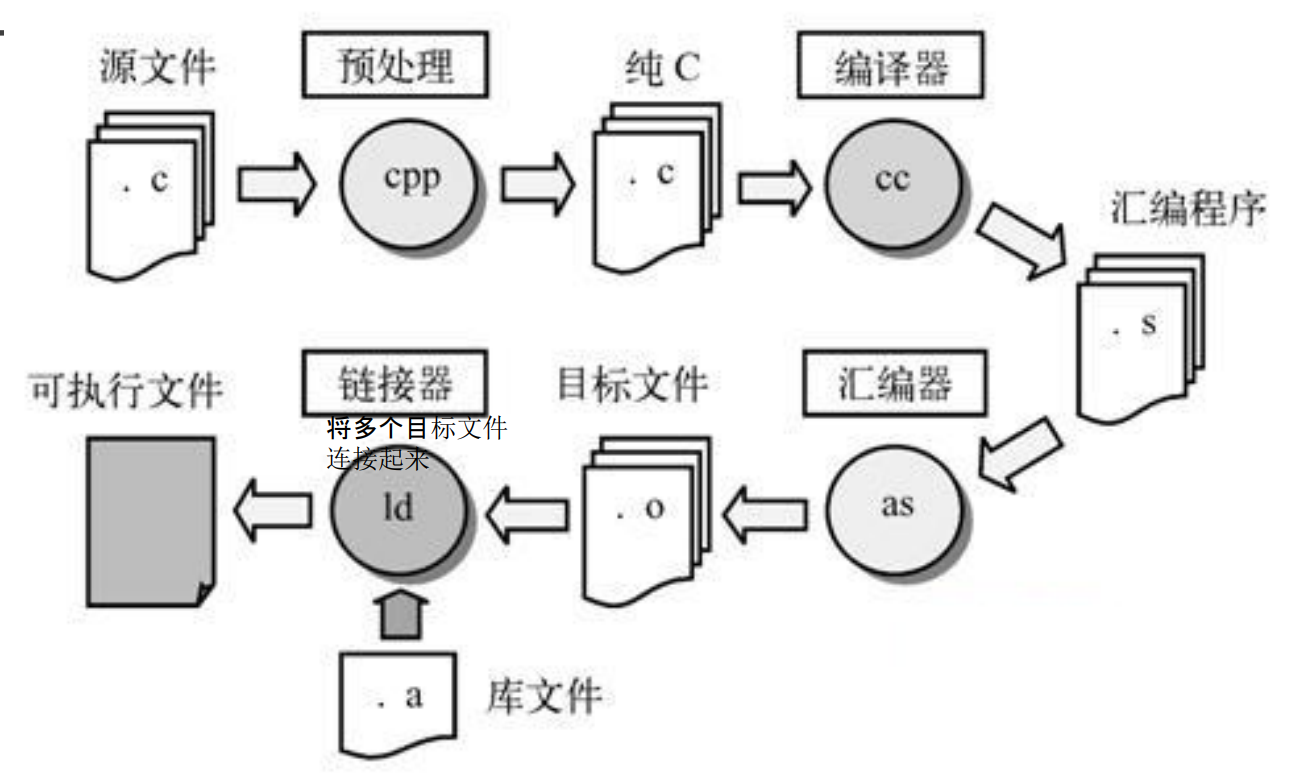
编译的四个阶段
| 阶段 | 输入 | 输出 | 说明 |
|---|---|---|---|
| 预处理 | .c 源文件 | .i 预处理文件 | 处理 #include(头文件文本替换)、#define(宏展开)、条件编译等 |
| 编译 | .i 预处理文件 | .s 汇编文件 | 将C代码翻译为汇编语言 |
| 汇编 | .s 汇编文件 | .o 目标文件 | 将汇编翻译为机器码 |
| 链接 | 多个.o + 库 | 可执行文件 | 合并目标文件和库,解析符号引用 |
头文件的处理
在预处理阶段,#include 指令会使预处理器按文件名找到对应头文件,用头文件的全部文本内容替换该行。这就是为什么预处理后文件体积会显著增大。
为什么需要链接
大型程序通常由多个源文件组成,每个源文件单独编译成 .o 目标文件。一个文件中的函数可能调用另一个文件中的函数(跨文件符号引用),链接器的作用就是:
- 将所有目标文件合并成一个可执行文件
- 解析跨文件的符号引用(函数调用、全局变量访问等)
- 将符号表和重定位表等信息写入可执行文件
静态库与动态库
| 静态库(.a) | 动态库/共享对象(.so) | |
|---|---|---|
| 链接时机 | 编译时,代码直接复制到可执行文件 | 运行时加载,可执行文件只包含引用 |
| 文件大小 | 生成的可执行文件较大 | 可执行文件较小 |
| 更新升级 | 需要重新编译整个程序 | 只需替换.so文件,无需重新编译 |
| 内存效率 | 每个进程各有一份拷贝 | 多个进程可共享同一份内存中的库代码 |
| 复用性 | 较高,降低模块间耦合 | 高,但可能有版本冲突 |
| 创建方式 | ar 工具打包 |
gcc -shared |
五、GCC & 文件扩展名
GCC常用选项
GCC已经从单一的C编译器发展为支持多语言的编译器集合(GNU Compiler Collection)。gcc 命令是前端,根据文件后缀自动调用相应的编译器。
阶段控制选项(对应编译四阶段)
gcc -E hello.c # 只预处理,输出到标准输出(生成.i文件内容)
gcc -S hello.c # 预处理+编译,生成汇编文件 hello.s
gcc -c hello.c # 预处理+编译+汇编但不链接,生成目标文件 hello.o
gcc hello.c # 全部执行(预处理+编译+汇编+链接),生成 a.out输出和调试选项
gcc -o outputfile hello.c # -o:指定输出文件名(默认a.out)
gcc -g hello.c # -g:产生调试符号信息(调试时必须)
gcc -O2 hello.c # -O/On:优化,O0无优化,O2常用优化级别
gcc -Wall hello.c # -Wall:显示所有警告信息路径和库选项
gcc -Idir hello.c # -I:指定额外的头文件搜索路径
gcc -Ldir -lname hello.c # -L:指定库搜索路径;-l:链接库(如-lm链接libm)
gcc -DMACRO=value hello.c # -D:定义宏(等价于代码中#define)常用示例
gcc -c hello.c # 只编译不链接
gcc file1.o file2.o -o myprogram # 链接多个.o为可执行文件
gcc -c -o main.o main.c # 编译并指定输出文件名
gcc -I./include -L./lib -lm -o prog main.c # 指定头文件和库路径,链接数学库文件扩展名(*)
GCC根据文件后缀自动判断语言和处理方式:
| 后缀 | 说明 |
|---|---|
.c |
C源代码,需要预处理 |
.cc .cpp .cxx .C |
C++源代码,需要预处理 |
.i |
C源代码,已经预处理过(不需要再预处理) |
.ii |
C++源代码,已经预处理过 |
.h .H .hh |
头文件 |
.s |
汇编代码(不需要预处理) |
.S |
汇编代码(需要预处理,可包含#include等) |
.o |
目标文件(Object file) |
.a |
静态库文件(Archive) |
.so |
动态库文件(Shared Object) |
.s和.S的区别:只有大小写之差,但.S会先经过预处理器,可以包含宏和头文件。
六、make、makefile & 预定义变量
1. make概述
当项目包含多个源文件时,手动逐个编译效率低下。make 是一个自动化构建工具,通过读取 Makefile(或makefile)文件来:
- 定义模块间的依赖关系
- 判断被维护文件的时序关系(修改时间新旧)
- 只重新编译发生变化的文件,实现增量编译
命令格式:make [-f Makefile] [option] [target]
make # 执行Makefile中第一个目标
make target # 执行指定目标
make clean # 执行清理目标
make -f MyMake # 指定其他Makefile文件2. Makefile语法
target ... : prerequisites ...
command核心规则:
- 顶格写的是规则(目标和依赖)
- Tab缩进(必须用Tab,不能用空格!)写的是命令
target:目标文件(要生成的文件)prerequisites:生成target所需的依赖文件或目标command:make需要执行的Shell命令
命令默认会回显(打印到屏幕),在命令前加
@可抑制回显。
示例:
hello : main.o kbd.o
gcc -o hello main.o kbd.o
main.o : main.c defs.h
cc -c main.c
kbd.o : kbd.c defs.h command.h
cc -c kbd.c
clean :
rm hello main.o kbd.o依赖链分析:hello 依赖 main.o 和 kbd.o,而这两个 .o 又依赖各自的 .c 和 .h。若修改了 defs.h,则 main.o 和 kbd.o 都需重新编译,然后 hello 重新链接。
3. 判断执行次序
make采用递归方式解析依赖:
- 在当前目录找
Makefile或makefile - 查找文件中第一个target(如示例中的
hello) - 如果target不存在,或依赖文件的修改时间比target更新,则执行command生成target
- 如果target依赖的
.o文件不存在,递归查找生成.o的规则并执行 - 类似于栈的过程——先满足底层依赖,再逐层构建顶层目标
4. 伪目标
clean :
rm hello main.o kbd.oclean 不是一个真实的文件,而是一个动作标签,称为伪目标。make无法生成它的依赖关系,只能通过显式指明目标(make clean)来触发。
问题:如果目录下恰好有一个名叫 clean 的文件,make会认为该目标已是最新而不执行。解决方案:
.PHONY: clean # 声明为伪目标,强制执行
clean:
rm hello main.o kbd.o常用伪目标:
| 目标 | 作用 |
|---|---|
all |
编译所有目标(通常作为第一个目标) |
clean |
清理生成的文件 |
install |
安装程序 |
uninstall |
卸载程序 |
check |
运行测试 |
5. 多目标(*)
多个目标依赖同一文件、命令大致相同时,可用 $@ 简化:
bigoutput littleoutput : text.g
generate text.g -$(subst output,,$@) > $@
# 等价于:
bigoutput : text.g
generate text.g -big > bigoutput
littleoutput : text.g
generate text.g -little > littleoutput$@ 代表当前正在构建的目标名,$(subst output,,$@) 将目标名中 “output” 替换为空。
6. 预定义变量(*)
Makefile内置的自动化变量,简化规则编写:
| 变量 | 含义 |
|---|---|
$< |
第一个依赖文件的名称 |
$? |
所有比目标新的依赖文件(以空格分隔) |
$+ |
所有依赖文件(以空格分隔,可能含重复) |
$^ |
所有依赖文件(以空格分隔,不含重复) |
$* |
不包括扩展名的目标文件名称 |
$@ |
目标的完整名称 |
$% |
若目标是归档成员,表示该成员的名称 |
最常用的是 $@(目标名)、$<(第一个依赖)、$^(全部依赖)。典型用法:
%.o : %.c
gcc -c $< -o $@7. 使用变量和模式规则简化Makefile
变量避免重复:
OBJECTS = main.o kbd.o command.o
edit: $(OBJECTS)
gcc -o edit $(OBJECTS)
clean:
rm edit $(OBJECTS)模式规则(%.o : %.c)自动生成编译规则,无需为每个 .o 单独写:
$(OBJECTS): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@从传统Makefile演进到使用变量和模式规则的版本,是从手动到自动化的关键一步。
ch3-1 System Programming
一、文件系统
本部分较长,重要的有:文件系统概念、VFS、硬软链接、系统调用和库函数、I/O等。
1. 文件和文件系统
文件
根据SUSv3标准:文件是一个能被写入或读取的对象,具有访问权限和类型等属性。在Linux中,文件就是一串字节流,系统不关心其内部结构。
文件系统的三种含义
| 含义 | 说明 | 示例 |
|---|---|---|
| 一种特定的文件格式 | 磁盘上组织数据的方式 | Ext4、FAT32、NTFS |
| 按特定格式格式化的块存储介质 | 已格式化的分区/磁盘 | “挂载文件系统” |
| OS中管理文件系统的机制和实现 | 内核中处理文件操作的代码 | VFS框架、Ext4驱动 |
考试中经常考查第三种含义——操作系统中用来管理文件系统及对文件进行操作的机制和实现。
2. VFS & VFS Model
VFS(Virtual File System Switch)
VFS是Linux文件系统的核心抽象层,作用:屏蔽系统空间中各种文件系统之间的差异,提供统一的文件操作接口。VFS仅存在于内存中,是内核的一部分。它让用户和程序可以用同样的命令和接口去操作不同格式的文件系统(Ext4、NTFS、NFS等),无需关心底层差异。
VFS Model(一定有一道题:四个组件及其作用)
| 组件 | 作用 |
|---|---|
| super block(超级块对象) | 存储某个磁盘某分区上已挂载文件系统的元信息,包括文件系统类型和参数 |
| inode对象(索引节点对象) | 记录真正的文件信息,文件在磁盘上按索引号(inode号)访问;每个文件对应一个inode |
| file对象(文件对象) | 记录通过 open 创建的文件描述符对应的状态信息(如文件偏移量、打开模式),而不是文件本身;文件 close 后才能释放file对象;同一文件被多次打开会有多个file对象 |
| dentry对象(目录项对象) | 表示文件/目录在目录中的信息,将文件名映射到对应的inode(目录名 → inode号) |
四者关系:super block → 整个文件系统;inode → 一个文件;file → 一次打开;dentry → 文件名到inode的桥梁。
3. 硬链接与软链接
| 硬链接(Hard Link) | 软链接/符号链接(Symbolic Link) | |
|---|---|---|
| 原理 | 创建新的目录项,与原文件共享同一个inode和数据块 | 存储目标文件的路径名,拥有独立的inode |
| 删除原文件 | 不影响,硬链接仍可用 | 链接失效(成为"悬挂链接") |
| 链接目录 | 不能链接目录(防止循环引用) | 可以链接目录 |
| 跨文件系统 | 不能跨文件系统 | 可以跨文件系统 |
| 系统调用 | link() |
symlink() |
硬链接本质:同一文件的多个名字(别名)。软链接本质:类似Windows快捷方式的独立文件。
4. 系统调用和库函数
| 系统调用 | 库函数 | |
|---|---|---|
| 本质 | Linux内核的对外接口,用户程序与内核之间的唯一接口 | 对系统调用的封装,提供更方便的接口 |
| 功能 | 提供最小接口,一个系统调用做一件事 | 提供复杂功能,一个库函数可能调用多个系统调用 |
| 形式 | 以C函数形式出现,定义在 <unistd.h> 等 |
以C函数形式出现,如 fread、printf |
| 例子 | read(), write(), open() |
fread() 内部调用 read(),还处理缓冲等 |
库函数依赖于系统调用。例如
printf最终通过write系统调用输出数据。
5. 无缓冲I/O和缓冲I/O
| 无缓冲I/O | 缓冲I/O | |
|---|---|---|
| 函数 | read / write 系统调用 |
标准I/O库(stdio)函数 |
| 操作对象 | 文件描述符(int fd) |
流(FILE * 指针) |
| 缓冲 | 每次调用直接进入内核(用户态↔内核态切换) | 在用户空间维护缓冲区,积累数据后才发起系统调用 |
| 标准来源 | POSIX.1 和 XPG3(非ANSI C) | ANSI C标准 |
| 效率 | 大数据块读写高效 | 减少系统调用次数,字符级操作也高效 |
| 灵活性 | 完全控制,适合底层操作 | 使用方便,适合常规操作 |
标准I/O库的三种缓冲模式:
| 模式 | 说明 | 典型场景 |
|---|---|---|
| 全缓冲 | 填满缓冲区后才发起系统调用 | 普通磁盘文件 |
| 行缓冲 | 遇到换行符 \n 时刷新 |
终端(stdin/stdout) |
| 无缓冲 | 数据立即写入(不经过库缓冲) | stderr |
缓冲区大小考量见后文性能对比——选对大小可带来数量级的性能提升。
6. I/O系统调用
文件描述符
文件描述符(file descriptor)是一个小的非负整数,内核用它标识进程打开的文件。<unistd.h> 中包含相关函数原型和常量。
三个预定义描述符:
| 常量 | 值 | 说明 |
|---|---|---|
STDIN_FILENO |
0 | 标准输入 |
STDOUT_FILENO |
1 | 标准输出 |
STDERR_FILENO |
2 | 标准错误 |
文件操作一般步骤:open → read/write → [lseek] → close
open / creat
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);
// 成功返回文件描述符(最小可用),失败返回 -1flags参数(按位或组合):
| Flag | 说明 |
|---|---|
O_RDONLY |
只读打开 |
O_WRONLY |
只写打开 |
O_RDWR |
读写打开 |
O_APPEND |
追加模式,每次写入前自动定位到文件末尾 |
O_CREAT |
文件不存在则创建(需提供mode参数) |
O_TRUNC |
若文件存在且可写,清空为0长度 |
O_EXCL |
与 O_CREAT 联用,文件已存在则失败(原子操作,防覆盖) |
creat是历史遗留函数,等价于open(pathname, O_WRONLY | O_CREAT | O_TRUNC, mode)。
mode参数:仅当flags含 O_CREAT 时提供,指定新文件的权限。mode_t 实际是八进制数,后三位分别代表:4=读, 2=写, 1=执行。
mode与umask(考试一般会考计算)
umask 是文件保护机制,新文件的实际权限 = mode & ~umask。
计算公式:
- 普通文件:
666 - umask= 最终权限(如umask=022→644,即rw-r--r--) - 目录文件:
777 - umask= 最终权限(如umask=022→755,即rwxr-xr-x)
常见umask值为022,屏蔽了"组写"和"其他人写"权限。
close
#include <unistd.h>
int close(int fd);
// 成功返回 0,失败返回 -1关闭文件描述符,释放内核资源。进程退出时所有fd自动关闭,但显式关闭是良好习惯。
read / write
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
// 返回:实际读到的字节数,文件尾返回 0,出错返回 -1
ssize_t write(int fd, const void *buf, size_t count);
// 返回:实际写入的字节数,出错返回 -1⚠️
read/write的返回值可能小于请求的字节数(信号中断、磁盘满等),典型写法是在循环中调用。简短示例(mycat.c的核心):
while ((n = read(STDIN_FILENO, buf, BUFSIZE)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
if (n < 0)
err_sys("read error");lseek
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
// 成功返回新的偏移位置,失败返回 -1| whence | 含义 |
|---|---|
SEEK_SET |
从文件开头偏移offset字节 |
SEEK_CUR |
从当前位置偏移offset字节 |
SEEK_END |
从文件末尾偏移offset字节 |
lseek只修改内核中记录的偏移量,不触发磁盘I/O。偏移量可以超过文件末尾(形成"空洞")。
dup / dup2
#include <unistd.h>
int dup(int oldfd);
// 返回新的文件描述符,指向oldfd同一文件表项;失败返回-1
int dup2(int oldfd, int newfd);
// 若newfd已打开先关闭,再将oldfd复制到newfd;成功返回newfd,失败返回-1复制后的两个描述符共享同一文件表项(共享偏移量和状态标志)。重定向示例:
int fd = open("4.txt", O_CREAT | O_RDWR);
dup2(fd, STDOUT_FILENO); // 将stdout重定向到4.txt
printf("hello world"); // 输出到4.txt而非屏幕
close(fd);fcntl(*)
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd);
int fcntl(int fd, int cmd, long arg);
int fcntl(int fd, int cmd, struct flock *lock);主要cmd参数:F_DUPFD(复制描述符)、F_GETFD/F_SETFD(获取/设置描述符标志如close-on-exec)、F_GETFL/F_SETFL(获取/设置文件状态标志)、F_GETLK/F_SETLK/F_SETLKW(文件锁)。
ioctl(*)
#include <sys/ioctl.h>
int ioctl(int d, int request, ...);设备控制的通用接口,用于执行设备特定操作(如设置波特率、调整终端尺寸等)。
7. 标准I/O库
流打开/关闭
#include <stdio.h>
FILE *fopen(const char *filename, const char *mode);
// 成功返回文件指针,失败返回 NULL
int fclose(FILE *stream);
// 成功返回 0,失败返回 -1(关闭前会先刷新缓冲区)| mode | 说明 |
|---|---|
"r" |
只读,文件必须存在 |
"w" |
只写,清空已有内容或创建新文件 |
"a" |
追加,保留已有内容,从末尾写入 |
"r+" |
读写,文件必须存在 |
"w+" |
读写,清空已有内容或创建新文件 |
"a+" |
读和追加 |
字符读写
int getc(FILE *fp); // 从流读一个字符(通常为宏)
int fgetc(FILE *fp); // 同上(函数实现)
int getchar(void); // 等价于 getc(stdin)
int putc(int c, FILE *fp); // 向流写一个字符(通常为宏)
int fputc(int c, FILE *fp); // 同上(函数实现)
int putchar(int c); // 等价于 putc(c, stdout)
// 返回:成功返回字符(get)或写入字符(put),失败/文件尾返回 EOF
getc和fgetc的区别:前者常实现为宏(效率高),后者是函数。ungetc可将一个字符"退回"输入流。
行读写
char *fgets(char *s, int size, FILE *stream);
// 读取最多 size-1 个字符,遇换行或EOF停止,末尾自动加 '\0'
// 成功返回 s,失败/EOF返回 NULL;换行符也会读入缓冲区
char *gets(char *s); // 不安全!无边界检查,已被C11移除
int fputs(const char *s, FILE *stream); // 写字符串,不自动加换行
int puts(const char *s); // 写字符串到stdout,自动加换行二进制读写
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
// 返回:实际成功读写的项数(可能小于 nmemb)读写数组和结构体示例:
float data[10];
if (fwrite(&data[2], sizeof(float), 4, fp) != 4) // 写4个float
err_sys("fwrite error");
struct { short count; long total; char name[64]; } item;
if (fwrite(&item, sizeof(item), 1, fp) != 1) // 写1个结构体
err_sys("fwrite error");直接读写结构体有字节序(endianness)和填充(padding)问题,跨平台需谨慎。
格式化I/O
// 输入
int scanf(const char *format, ...); // 从stdin读取
int fscanf(FILE *stream, const char *format, ...); // 从流读取
int sscanf(const char *str, const char *format, ...); // 从字符串读取
// 输出
int printf(const char *format, ...); // 输出到stdout
int fprintf(FILE *stream, const char *format, ...); // 输出到流
int sprintf(char *str, const char *format, ...); // 输出到字符串建议:先用
fgets读一行,再用sscanf解析,比直接用scanf更易处理错误。
流定位
int fseek(FILE *stream, long int offset, int whence); // 与lseek参数一致
long ftell(FILE *stream); // 获取文件指针当前位置
void rewind(FILE *stream); // 等价于 fseek(fp, 0, SEEK_SET)流刷新
int fflush(FILE *stream); // 将缓冲区数据立即写入内核流与文件描述符互转(*)
int fileno(FILE *fp); // 获取流底层的文件描述符
FILE *fdopen(int fildes, const char *mode); // 从文件描述符创建流这两个函数在需要混用标准I/O函数和系统调用时很有用。
8. 其他系统调用
stat / fstat / lstat
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *filename, struct stat *buf); // 通过文件名,跟随符号链接
int fstat(int filedes, struct stat *buf); // 通过已打开fd
int lstat(const char *file_name, struct stat *buf); // 通过文件名,不跟随符号链接
// 成功返回 0,失败返回 -1三个函数的区别:
stat跟随符号链接(获取目标文件信息);lstat不跟随(获取链接本身的信息);fstat通过已打开的fd获取。
struct stat 重点属性:
struct stat {
mode_t st_mode; /* 文件类型和权限(含SUID/SGID/Sticky bit)*/
ino_t st_ino; /* inode号 */
nlink_t st_nlink; /* 硬链接计数 */
uid_t st_uid; /* 所有者用户ID */
gid_t st_gid; /* 所有者组ID */
off_t st_size; /* 文件大小(字节)*/
time_t st_atime; /* 最后访问时间(access time)*/
time_t st_mtime; /* 最后修改时间(modification time — 内容修改)*/
time_t st_ctime; /* 最后状态变更时间(change time — 权限等元数据修改)*/
};判断文件类型的宏(定义在 <sys/stat.h>,从 st_mode 提取类型):
| 宏 | 对应文件类型 |
|---|---|
S_ISREG() |
普通文件 |
S_ISDIR() |
目录 |
S_ISCHR() |
字符特殊文件 |
S_ISBLK() |
块特殊文件 |
S_ISFIFO() |
FIFO(命名管道) |
S_ISLNK() |
符号链接(仅 lstat 有效) |
S_ISSOCK() |
套接字 |
文件权限扩展:SUID / SGID / Sticky bit
| 权限位 | 含义 |
|---|---|
| SUID(S_ISUID, 04000) | 设置在可执行文件上,任何用户执行该程序时,有效用户ID提升为文件属主的权限(如 /usr/bin/passwd 以root权限运行) |
| SGID(S_ISGID, 02000) | 设置在可执行文件上,执行时有效组提升为文件属组;设置在目录上,目录中新建文件继承目录的组ID |
| Sticky bit(S_ISVTX, 01000) | 设置在目录上(如 /tmp 为 drwxrwxrwt),只有文件所有者和root能删除目录中的文件 |
设置方法:chmod u+s(SUID)、chmod g+s(SGID)、chmod o+t(Sticky)。典型SUID命令是 su、sudo、passwd。
access
#include <unistd.h>
int access(const char *pathname, int mode);
// 成功返回 0,失败返回 -1mode 取值:R_OK(可读)、W_OK(可写)、X_OK(可执行)、F_OK(是否存在)。
access按实际用户ID测试权限(而open按有效用户ID),SUID程序中用于安全检查。
chmod / fchmod
int chmod(const char *path, mode_t mode); // 通过文件名修改权限
int fchmod(int fildes, mode_t mode); // 通过文件描述符修改权限
// 成功返回 0,失败返回 -1chown / fchown / lchown
int chown(const char *path, uid_t owner, gid_t group);
int fchown(int fd, uid_t owner, gid_t group);
int lchown(const char *path, uid_t owner, gid_t group); // 不跟随符号链接
// 成功返回 0,失败返回 -1Shell命令:
chown user:group file(更改属主和属组),chgrp group file(只更改属组)。
umask
mode_t umask(mode_t mask);
// 返回:之前的 umask 值设置进程的文件权限掩码,影响后续创建的文件的默认权限。如:umask(S_IWGRP | S_IWOTH) 屏蔽组写和其他人写。
link / unlink(硬链接)
int link(const char *oldpath, const char *newpath); // 创建硬链接,成功返回0
int unlink(const char *pathname); // 删除目录项,链接计数-1
unlink只当链接计数降为0且无进程打开该文件时,内核才真正释放磁盘空间。
symlink / readlink(软链接)
int symlink(const char *oldpath, const char *newpath); // 创建符号链接
int readlink(const char *path, char *buf, size_t bufsiz); // 读取链接指向的路径
// readlink 返回放入缓冲区的字符数(不会在末尾加 '\0',调用者需处理)目录操作(*)
int mkdir(const char *pathname, mode_t mode); // 创建目录,权限受umask影响
int rmdir(const char *pathname); // 删除空目录(非空失败)
int chdir(const char *path); // 更改当前工作目录
int fchdir(int fd); // 通过fd更改工作目录
char *getcwd(char *buf, size_t size); // 获取当前工作目录的绝对路径<dirent.h> 中的目录流操作:
DIR *opendir(const char *name); // 打开目录,失败返回NULL
int closedir(DIR *dir); // 关闭目录流
struct dirent *readdir(DIR *dir); // 读取下一个目录项
off_t telldir(DIR *dir); // 查看当前偏移量
void seekdir(DIR *dir, off_t offset); // 跳转到指定偏移量目录扫描程序(*)— 标准模式
DIR *dp;
struct dirent *entry;
if ((dp = opendir(dir)) == NULL)
err_sys("can't open dir");
while ((entry = readdir(dp)) != NULL) {
lstat(entry->d_name, &statbuf); // 用lstat而非stat
if (S_ISDIR(statbuf.st_mode))
/* 是目录 */
else
/* 非目录 */
}
closedir(dp);用
lstat而非stat是为了避免跟随符号链接,正确判断链接文件本身的类型。
二、文件锁(#)
多个进程同时操作同一文件时需要锁机制来协调。
分类
| 类型 | 说明 |
|---|---|
| 记录锁(record lock) | 锁定文件的一部分区域(而非整个文件),通过 fcntl 实现 |
| 劝告锁(advisory lock) | 检查和加锁由应用程序自己控制;不合作的进程可以无视锁直接操作 |
| 强制锁(mandatory lock) | 检查和加锁由内核强制执行,违反锁的操作会被阻塞或失败 |
| 共享锁(shared lock) | 多个进程可以同时持有(如读锁),允许一起读但不允许修改 |
| 排他锁(exclusive lock) | 同一时刻只有一个进程可以持有(如写锁) |
fcntl 记录锁
#include <fcntl.h>
int fcntl(int fd, int cmd, struct flock *lock);
struct flock {
short l_type; /* F_RDLCK(共享读锁) / F_WRLCK(排他写锁) / F_UNLCK(解锁) */
short l_whence; /* SEEK_SET / SEEK_CUR / SEEK_END */
off_t l_start; /* 锁定区域起始偏移 */
off_t l_len; /* 锁定长度(0表示到文件尾)*/
pid_t l_pid; /* 持有锁的进程PID(F_GETLK 使用)*/
};cmd 参数:
| cmd | 说明 |
|---|---|
F_GETLK |
检查是否可以加锁(探测),不实际加锁 |
F_SETLK |
加锁或解锁,非阻塞,无法获得锁时立即返回错误 |
F_SETLKW |
加锁或解锁,阻塞等待直到获得锁(W = wait) |
实际开发中劝告锁更常用;强制锁需挂载时指定
-o mand且文件需设置SGID位。
ch4-2 Kernel Driver
一、内核相关概念
内核定义
内核是操作系统的核心组成部分,负责管理硬件资源和向用户程序提供抽象接口。Linux内核的能力覆盖:
| 能力 | 说明 |
|---|---|
| 内存管理 | 虚拟内存、页面分配与回收 |
| 文件系统 | VFS抽象层,支持多种文件系统 |
| 进程管理 | 进程创建、调度、终止 |
| 多线程支持 | 内核级线程(LWP) |
| 抢占式 | 高优先级任务可抢占CPU |
| 多处理支持 | SMP/NUMA架构支持 |
Linux内核区别于商业UNIX:①单内核+模块支持 ②免费/开源 ③支持多种CPU,硬件兼容能力极强 ④内核源码是学习现代操作系统的绝佳教材。
单内核 vs 微内核
| 类型 | 结构 | 通信方式 | 典型代表 |
|---|---|---|---|
| 单内核 | 一个大进程,内部划分为若干模块,运行时是独立二进制文件 | 直接调用函数 | Linux |
| 微内核 | 内核各部分作为独立进程在特权态运行 | 消息传递(IPC) | Minix, QNX |
Linux虽然是单内核,但通过**可加载模块(LKM)**机制,可动态加载/卸载内核功能,兼具微内核的灵活性和单内核的高效性。
内核层次结构
应用程序(用户空间)
↓ 系统调用
┌─────────────────────────┐
│ VFS(虚拟文件系统) │
│ 进程管理 / 内存管理 │
│ 网络协议栈 │
│ 设备驱动 │
│ Arch(体系结构相关代码) │
└─────────────────────────┘
↓
硬件层次结构从上到下:用户空间 → 系统调用接口 → 内核子系统 → 体系结构相关抽象 → 硬件。
二、驱动与模块
驱动概述
驱动的三种存在形式:
- 集成在内核源码中 — 直接编译进内核
- 第三方开发的驱动 — 单独编译成模块 .ko 文件
- 编译驱动需要内核头文件支持
驱动可以静态编译进内核(Y),也可以作为模块动态加载(M)。
模块加载命令
| 命令 | 层次 | 说明 |
|---|---|---|
insmod <module.ko> |
底层 | 直接加载模块文件,需要手动处理依赖 |
rmmod |
底层 | 卸载模块 |
modprobe <模块名> |
高层 | 自动处理依赖关系,按 modules.dep 依次加载 |
modprobe -r <模块名> |
高层 | 卸载模块及其依赖 |
其他命令:
| 命令 | 作用 |
|---|---|
lsmod |
列出所有已加载的内核模块(等价于 cat /proc/modules) |
modinfo |
查看模块的信息(作者、许可、参数等) |
depmod |
生成模块依赖关系文件 |
模块依赖
定义:模块A引用模块B导出的符号(函数或变量),则称模块B被模块A引用。
如果要装载模块A,必须先装载模块B。
modprobe可自动按需加载/卸载依赖模块。
模块间通信
模块间可以:
- 共享变量、数据结构
- 调用对方导出的功能函数
通过 EXPORT_SYMBOL(name) 或 EXPORT_SYMBOL_GPL(name) 导出符号。导出的符号出现在 /proc/kallsyms 中。
模块间依赖知识点:①导出的符号有两种 —
EXPORT_SYMBOL(任意模块可见)和EXPORT_SYMBOL_GPL(仅GPL许可模块可见)②查看导出符号的命令:cat /proc/kallsyms③符号必须在模块文件的全局部分导出,不能在函数内部导出 ④模块只能使用内核或其他模块导出的符号,不能使用C标准库。
#include <linux/module.h>
EXPORT_SYMBOL(add_integer); // 对任意模块可见
EXPORT_SYMBOL_GPL(sub_integer); // 只对GPL许可的模块可见三、内核模块 vs C语言应用程序
| C语言程序 | Linux内核模块 | |
|---|---|---|
| 运行空间 | 用户空间 | 内核空间 |
| 入口 | main() |
module_init() 指定的函数 |
| 出口 | 无(或 return) |
module_exit() 指定的函数 |
| 运行方式 | 直接在shell执行 | insmod / modprobe 加载 |
| 调试 | gdb | kdbug, kdb, kgdb 等内核调试器 |
模块编写注意事项:①不能使用C标准库(
printf→printk)②没有内存保护(野指针直接崩溃系统)③内核栈很小(通常4KB或8KB,避免深层递归和大局部变量)④并发考虑(多CPU、中断上下文)。
最简单的内核模块
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
static int __init hello_init(void)
{
printk(KERN_INFO "Hello world\n");
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_INFO "Goodbye world\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");关键要点:
__init标记:该函数只在初始化时使用,加载后内存被释放__exit标记:该代码仅用于模块卸载module_init(函数名)/module_exit(函数名):声明入口和出口MODULE_LICENSE必须指定,否则内核认为模块是"污染的"
四、/proc 文件系统与驱动交互(⭐ 主观题)
/proc 是伪文件系统,是内核模块与用户空间交互的主要方式之一。不是普通意义上的文件系统。
- 通过
/proc,可用标准Unix系统调用(open、read、write、ioctl)访问内核数据 - 可用
cat、more等命令查看/proc文件中的信息 - 用户可通过
/proc获取系统信息和改变内核参数 - 当调试程序或获取进程状态时,/proc 是强有力的支持者
/proc操作函数:
| 函数 | 作用 |
|---|---|
create_proc_entry() |
创建一个文件 |
proc_symlink() |
创建符号链接 |
proc_mknod() |
创建设备文件 |
proc_mkdir() |
创建目录 |
remove_proc_entry() |
删除文件或目录 |
现代内核更推荐使用
seq_file接口或debugfs,/proc主要用于内核本身的信息展示。
五、字符设备驱动(⭐ 重重点 — 主观题)
建立字符型设备的具体步骤是主观题,必须完整掌握整个流程。
Linux系统将设备分为三种类型:
| 类型 | 访问方式 | 典型设备 |
|---|---|---|
| 字符设备 | 以字节流顺序访问 | 串口、键盘、LCD、LED、触摸屏 |
| 块设备 | 以固定大小块随机访问 | 硬盘、SD卡 |
| 网络接口设备 | 通过套接字接口访问 | 网卡 |
分类原则是设备读写操作的特征差异。
字符设备驱动对上接口
字符设备驱动暴露给用户空间的四个核心操作:
| 接口 | 原型 | 说明 |
|---|---|---|
read |
ssize_t (*read)(struct file *, char __user *, size_t, loff_t *) |
从设备读取数据 |
write |
ssize_t (*write)(struct file *, const char __user *, size_t, loff_t *) |
向设备写入数据 |
flush |
int (*flush)(struct file *) |
刷新设备缓冲区 |
ioctl |
int (*ioctl)(struct inode *, struct file *, unsigned int, unsigned long) |
设备控制命令(万能接口) |
__user标记表示指针来自用户空间,内核代码不能直接解引用,需用copy_from_user/copy_to_user。
两个基本结构:file 与 inode
| 结构体 | 说明 | 关键成员 |
|---|---|---|
struct file |
代表一个打开的文件实例 | 文件描述符标志、读写位置(f_pos)、private_data(驱动私有数据指针) |
struct inode |
代表文件元数据(一个真实的文件实体) | i_rdev(设备号)、权限、大小等 |
struct file是进程私有的(以 COW 方式与子进程共享);struct inode全局唯一,代表磁盘上的真实文件。
建立字符设备的具体步骤(⭐ 主观题,6步)
第一步:申请设备号
↓
第二步:定义 file_operations 结构体(实现 read/write/open/release 等函数)
↓
第三步:创建并初始化 cdev 结构体
↓
第四步:将 cdev 注册到系统,与设备号绑定(cdev_add)
↓
第五步:实现 file_operations 中的各个函数
↓
第六步:在 /dev 中用 mknod 创建设备文件,绑定到设备号第一步:申请设备号
一个字符设备或块设备都有主设备号和次设备号,统称设备号。
| 概念 | 说明 |
|---|---|
| 主设备号(major) | 标识一个特定的驱动程序(如 8 表示 SCSI 磁盘) |
| 次设备号(minor) | 标识使用该驱动的各设备(如 sda=0, sda1=1) |
dev_t dev; // 32位类型,高12位为主设备号,低20位为次设备号
int MAJOR(dev_t dev);
int MINOR(dev_t dev);
// 静态申请(已知主设备号)
int register_chrdev_region(dev_t first, unsigned int count, char *name);
// 动态分配(推荐,内核自动分配空闲主设备号)
int alloc_chrdev_region(dev_t *dev, unsigned int firstminor,
unsigned int count, char *name);
// 释放
void unregister_chrdev_region(dev_t first, unsigned int count);具体函数不考读代码,但要知道设备号是什么、主次设备号各自的含义。
第二步:定义 file_operations 结构体
struct file_operations scull_fops = {
.owner = THIS_MODULE, // 防止模块在使用中被卸载
.llseek = scull_llseek,
.read = scull_read,
.write = scull_write,
.ioctl = scull_ioctl,
.open = scull_open,
.release = scull_release,
};未实现的函数指针可设为 NULL,内核会使用默认行为。
第三步:创建并初始化 cdev
struct cdev 是内核中描述字符设备的对象,包含所有字符设备的共有特性:
// 方式1:动态分配
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops = &my_fops;
// 方式2:静态初始化
void cdev_init(struct cdev *cdev, struct file_operations *fops);第四步:注册 cdev 到系统
int cdev_add(struct cdev *dev, dev_t num, unsigned int count);
// 成功返回 0,将 cdev 与设备号绑定并加入内核
void cdev_del(struct cdev *dev);
// 移除注册应在
cdev_add成功后再创建设备文件。
第五步:实现 file_operations 中的函数
以 open 为例,核心技巧是使用 container_of 从 cdev 获取自定义设备结构体:
int scull_open(struct inode *inode, struct file *filp) {
struct scull_dev *dev;
// container_of:从成员指针反推外层结构体指针
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev; // 存入私有指针,供 read/write 使用
if ((filp->f_flags & O_ACCMODE) == O_WRONLY) {
scull_trim(dev); // 只写打开则清空设备
}
return 0;
}
container_of是内核最核心的技巧之一:通过结构体成员的地址、结构体类型、成员名,计算出外层结构体的地址。
第六步:创建设备文件并绑定
Linux 一切皆文件,安装驱动后必须创建设备节点(文件),应用程序才能通过设备节点操作底层驱动:
mknod /dev/scull0 c $major 0
# 设备名, c=字符设备(b=块设备), 主设备号, 次设备号
# 查看已注册的设备号
cat /proc/devices驱动建立后用户态程序如何使用
用户态程序通过标准文件操作访问设备,与操作普通文件完全一致:
int fd = open("/dev/scull0", O_RDWR); // 打开设备文件
char buf[1024];
read(fd, buf, sizeof(buf)); // 从设备读取数据
write(fd, "hello", 5); // 向设备写入数据
ioctl(fd, CMD_XXX, &arg); // 发送控制命令
close(fd); // 关闭设备整个接口原理:用户程序 → open/read/write/ioctl 系统调用 → VFS → file_operations 中的驱动函数 → 硬件操作。VFS 将用户态的文件操作请求路由到对应驱动的具体函数。
ch5G OpenEuler
基本概念
- 2019年底,EulerOS开源,成为OpenEuler(openEuler)。
- OpenEuler是一款通用服务器操作系统(不是专用系统)。
- 支持多种处理器架构,并非仅支持鲲鹏。
- 指令集为 ARMv8-64。
- 对鲲鹏处理器做了专项优化。
- 基于 Linux 4.19 内核。
四大优势
| 优势 | 说明 |
|---|---|
| 多核调度(NUMA-aware) | 提供NUMA-aware解决方案,提升多核调度性能 |
| 软硬件协同(KAE) | 鲲鹏加速引擎插件,使能鲲鹏硬件加速能力 |
| 轻量容器(iSulad) | 轻量级容器引擎,内存开销更小,并发性能更高 |
| 智能调优(A-Tune) | 智能优化引擎,智能决策、自动调优 |
问四点优势 → 四个词:多核调度、软硬件协同、iSulad、A-Tune。
关键知识点
毕昇JDK
毕昇JDK是一款针对ARM架构优化的高性能OpenJDK发行版:
| 优化项 | 说明 |
|---|---|
| ARM64优化 | dmb 指令消除等,提升整体性能 |
| 快速序列化技术 | 提升序列化、反序列化性能 |
| GC优化 | 减少系统卡顿(停顿时间更短) |
| 性能提升 | SpecJBB 基准测试提升 20% |
线程间通信 ITC
互斥机制 — 自旋锁
- 互斥机制主要使用自旋锁来实现
- openEuler 提供了 NUMA感知队列自旋锁(NUMA-aware queue spinlock)实现互斥机制
- 使用 CAN锁(Compact NUMA-aware Lock)代替 Qspinlock 中的 MCS 队列
- 减小了 NUMA 体系结构中使用自旋锁的跨节点缓存开销
同步机制 — 信号量(Semaphore)
- 同步机制主要使用信号量来实现
- openEuler 中提供 down 原语与 up 原语
down:获取信号量(P操作,可能阻塞等待)up:释放信号量(V操作,可能唤醒等待者)- 能够实现线程间的同步运行
进程间通信 IPC
openEuler 增强了两种进程间通信机制:
| IPC机制 | 说明 |
|---|---|
| 共享内存(Shared Memory) | 多个进程共享同一块物理内存区域,速度快,适合大数据量通信 |
| 消息传递(Message Passing) | 进程间通过发送/接收消息来交换数据,安全可控 |
内存页相关说明
| 知识点 | 说明 |
|---|---|
| 页表项大小 | 各级页表的页表项大小为 8B(8字节) |
| 标准大页 | 将标准大页封装为一个**伪文件系统(hugetlbfs)**提供给用户程序申请并访问 |
| 页面换出策略 | 采用 LRU(Least Recently Used,最近最久未使用)策略选择换出页 |
| 页面预测 | 页在未来被访问的概率只能预测,不能精准判断 |
鲲鹏处理器(Kunpeng Processor)
| 属性 | 说明 |
|---|---|
| 指令集 | 基于 ARMv8-64 位 RISC(精简指令集)指令集开发 |
| 类型 | 通用处理器 |
| 通用寄存器 | X0 ~ X30(31个,64位) |
| 其他寄存器 | 特殊寄存器 + 系统寄存器 |
| 架构特点 | 使用大量寄存器,ARM精简指令集 |
KAE(鲲鹏加速引擎)
KAE(Kunpeng Accelerator Engine,鲲鹏加速引擎)插件使能 Kunpeng 硬件加速能力,包括:
| 功能 | 说明 |
|---|---|
| 对称/非对称加密 | 硬件加速加密算法 |
| 数字签名 | 硬件加速签名验签 |
| 压缩解压缩 | 硬件加速数据压缩,用于加速 SSL/TLS 应用和数据压缩 |
KAE 体现了 openEuler 的"软硬件协同"优势。
openEuler 的增强
openEuler 对通用 Linux 操作系统作了增强,为充分发挥鲲鹏处理器优势,主要在以下四个方面:
| 增强方向 | 说明 |
|---|---|
| 多核调用技术 | NUMA感知队列自旋锁,CAN锁优化 |
| 软硬件协同 | KAE 鲲鹏加速引擎 |
| 轻量级虚拟化 | iSulad 轻量级容器引擎(全场景解决方案) |
| 指令集优化和智能优化引擎 | A-Tune 智能调优 |
其他特性
- 有内存管理预测机制
- 有内存共享机制
- 使用精简指令集(ARM架构)
- 没有神经网络加速引擎
常见判断题
下列有关openEuler说法错误的是?
C. 仅支持Kunpeng处理器 → 错误(支持x86、ARM、RISC-V等多种处理器架构)F. A-Tune从整体上看并不是一个C/S架构 → 错误(A-Tune是C/S架构)




